홈서버 장애 분석 #1
분류: home-server
장애 발생 알림
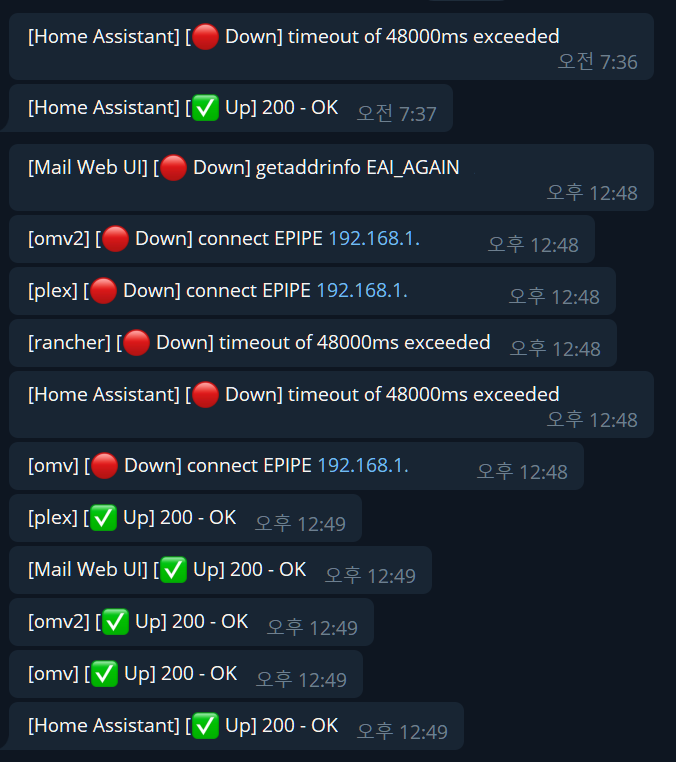
- uptimekuma 의 오류 알림이 텔레그램으로 전달됐다.
- 평소에도 1건씩 발생하지만 오류 5건이 동시 발생한 것은 처음이다.
netdata 대시보드 확인

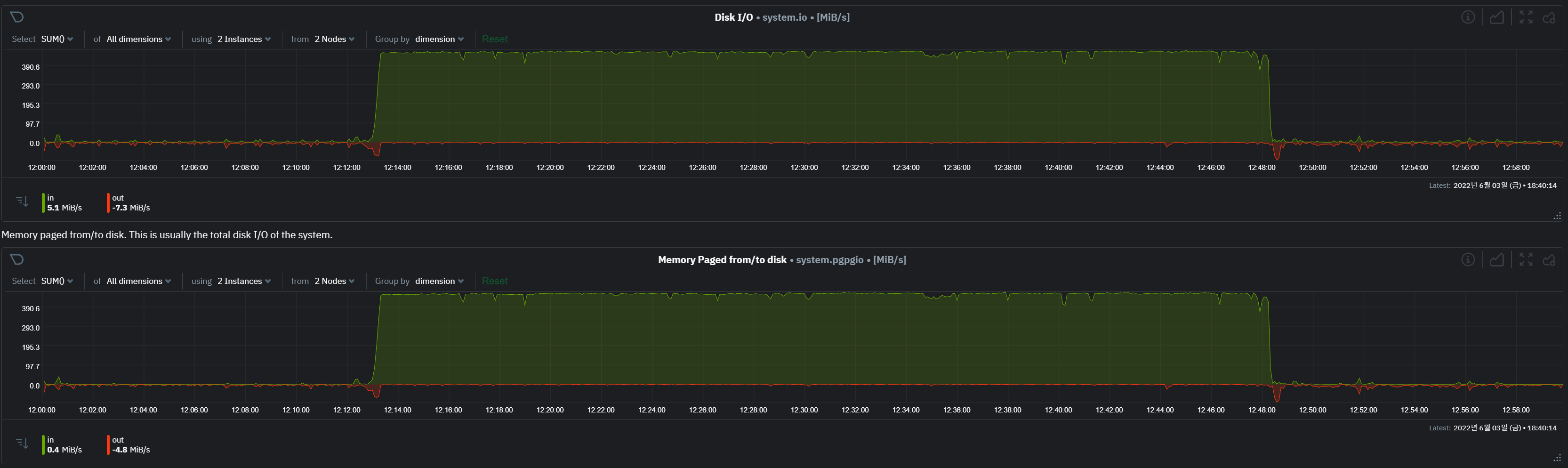
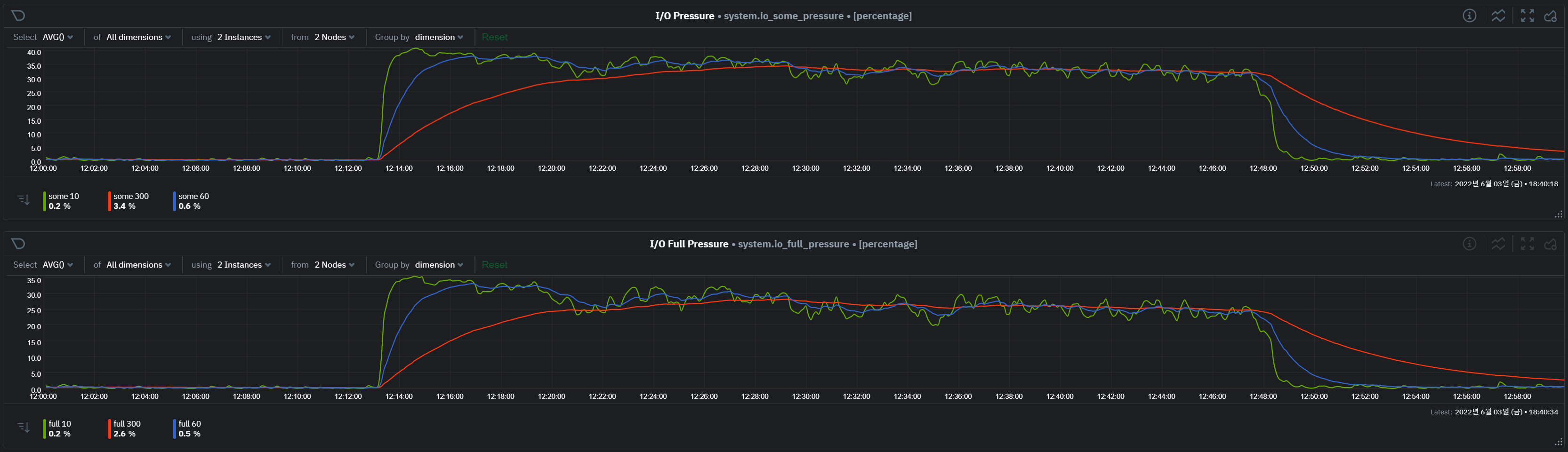

- cpu io wait 및 disk io 사용량이 높음. paging 발생량 높음.
- 메모리 사용량은 큰 변화가 없으나 이는 vm 할당량이므로 큰 의미 없음. (각 vm에는 netdata가 설치되어 있지 않다.)
grafana 확인
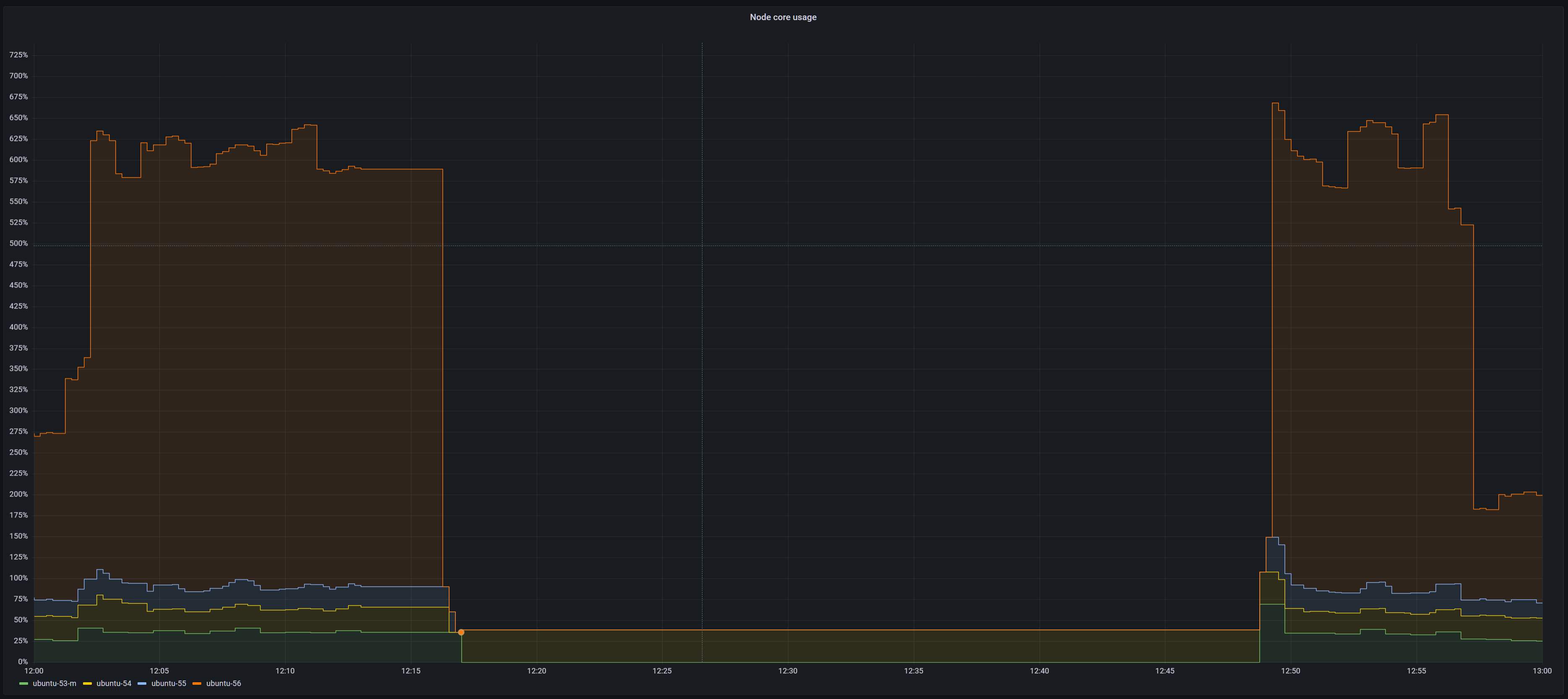
- 문제가 발생한 시점에 정상적으로 데이터가 수집되지 않았다.
문제가 있는 disk 확인
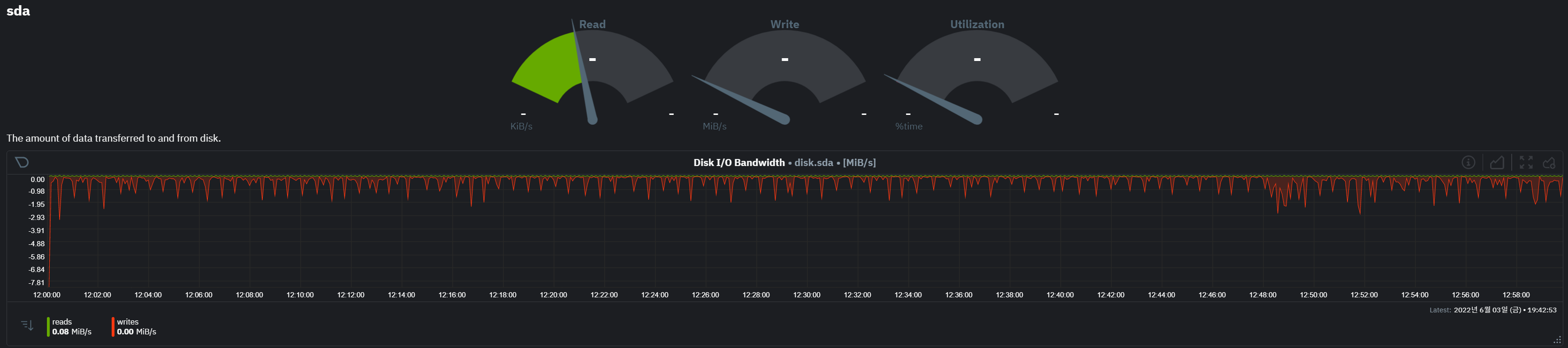
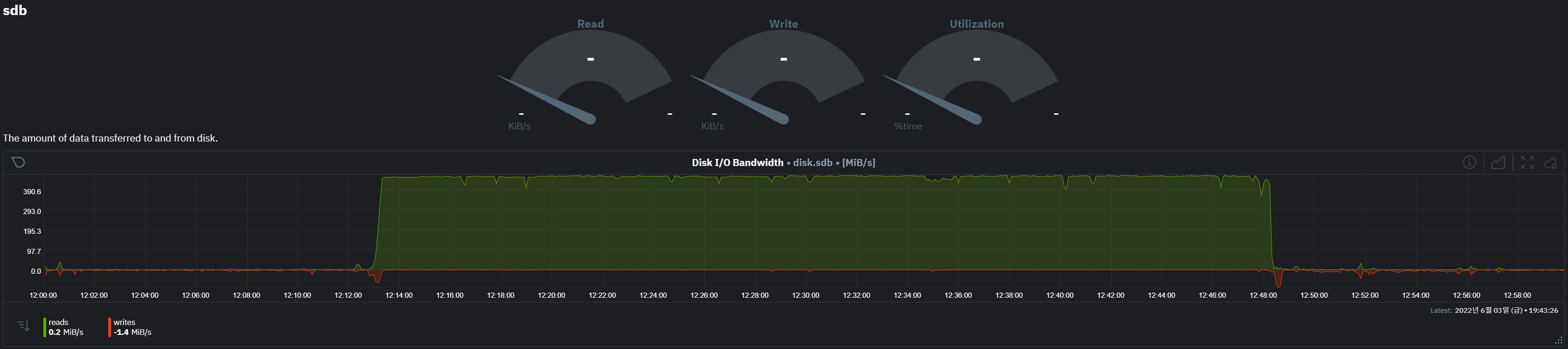
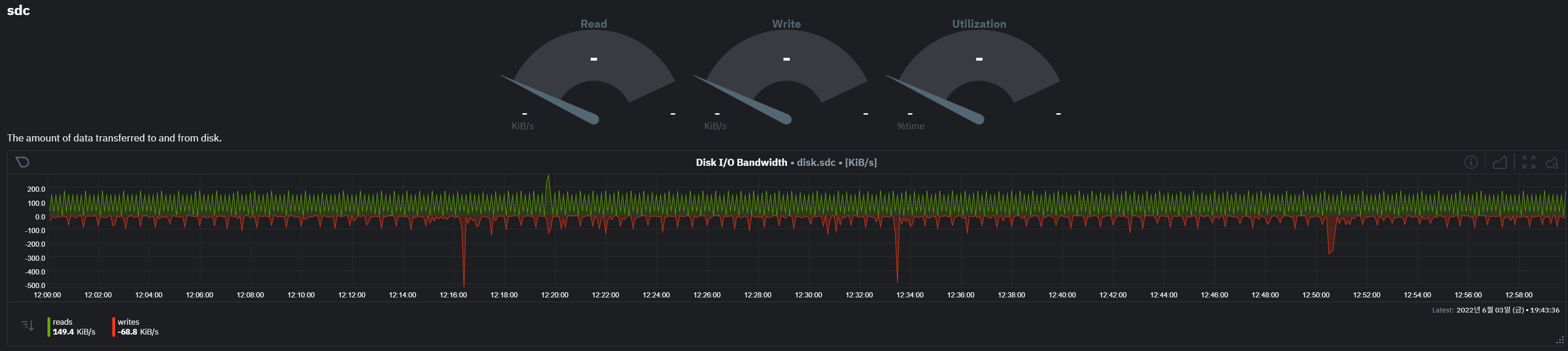
- 문제가 있던 노드에는 4개 디스크가 있으며 sdb 디스크에만 이상 수치를 보임
- sdb에는 vm의 disk 볼륨들이 할당되어 있음
문제가 있는 vm 확인
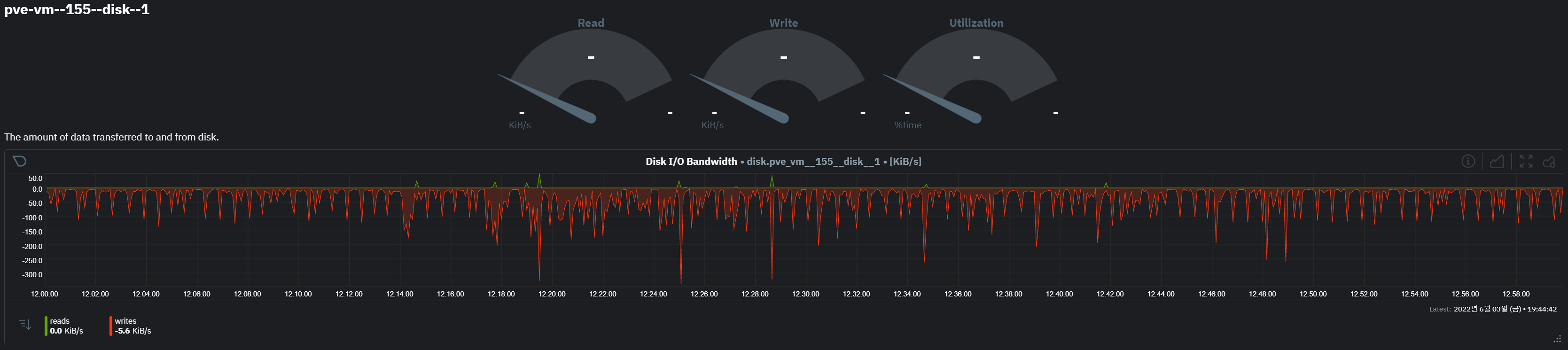
vm 155
vm 156
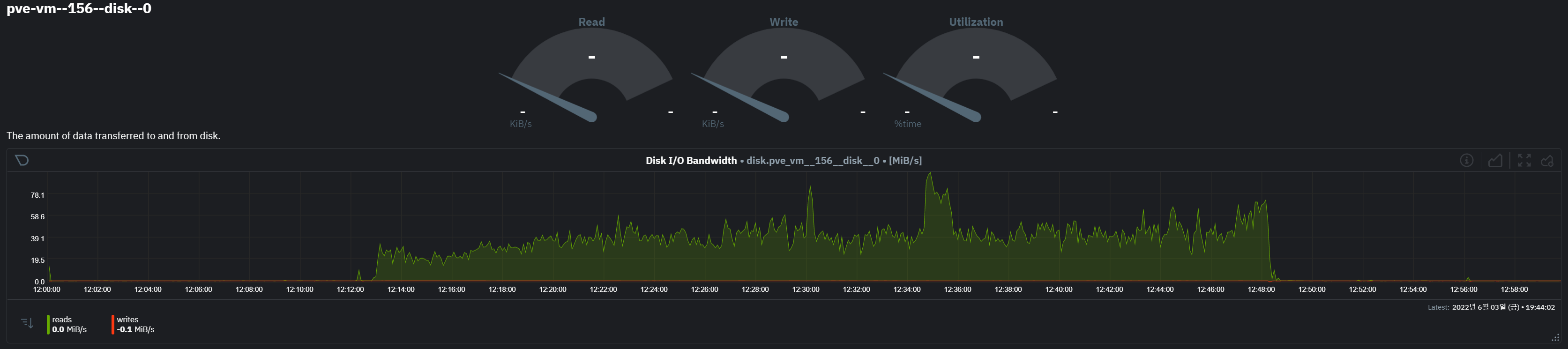
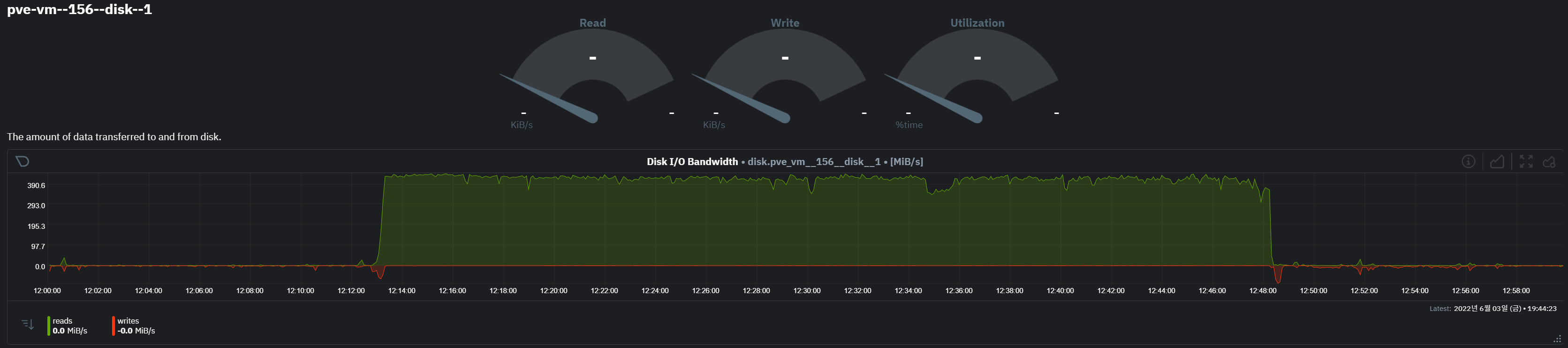
- vm 156 의 disk 에서 많은 io 발생
- disk-0 에는 os, disk-1 에는 docker 용 볼륨이 별도 할당되어 있다.
- 특히 disk-1의 read 대량 발생 구간 시작과 끝에 write i/o가 일부 발생한 것으로 확인됨
vm 156 확인
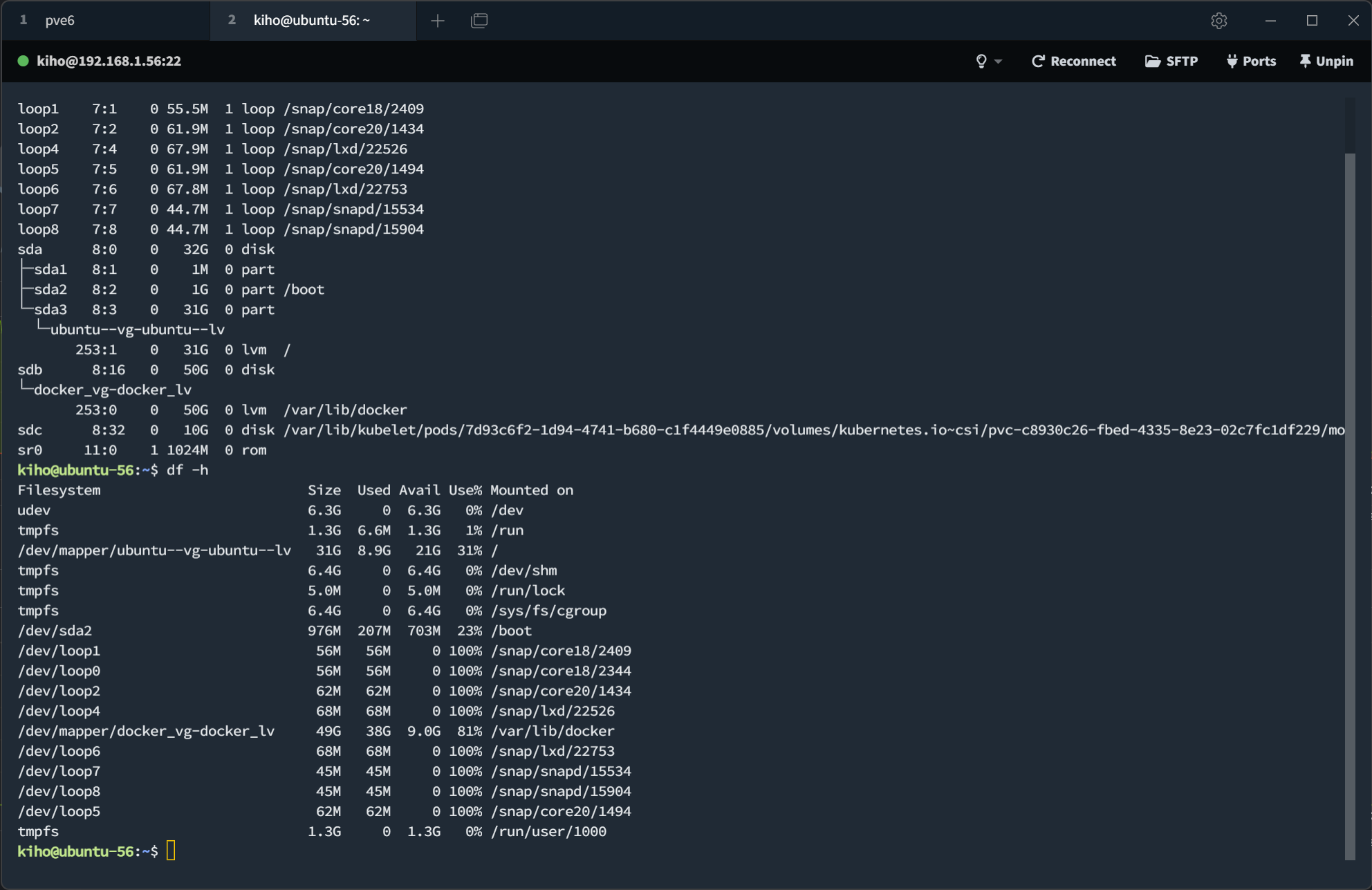
- docker용 볼륨 (/dev/sdb = docker_lv) 에 9GB 정도 여유공간이 있지만, 이미 자연해소된 이후의 확인값임
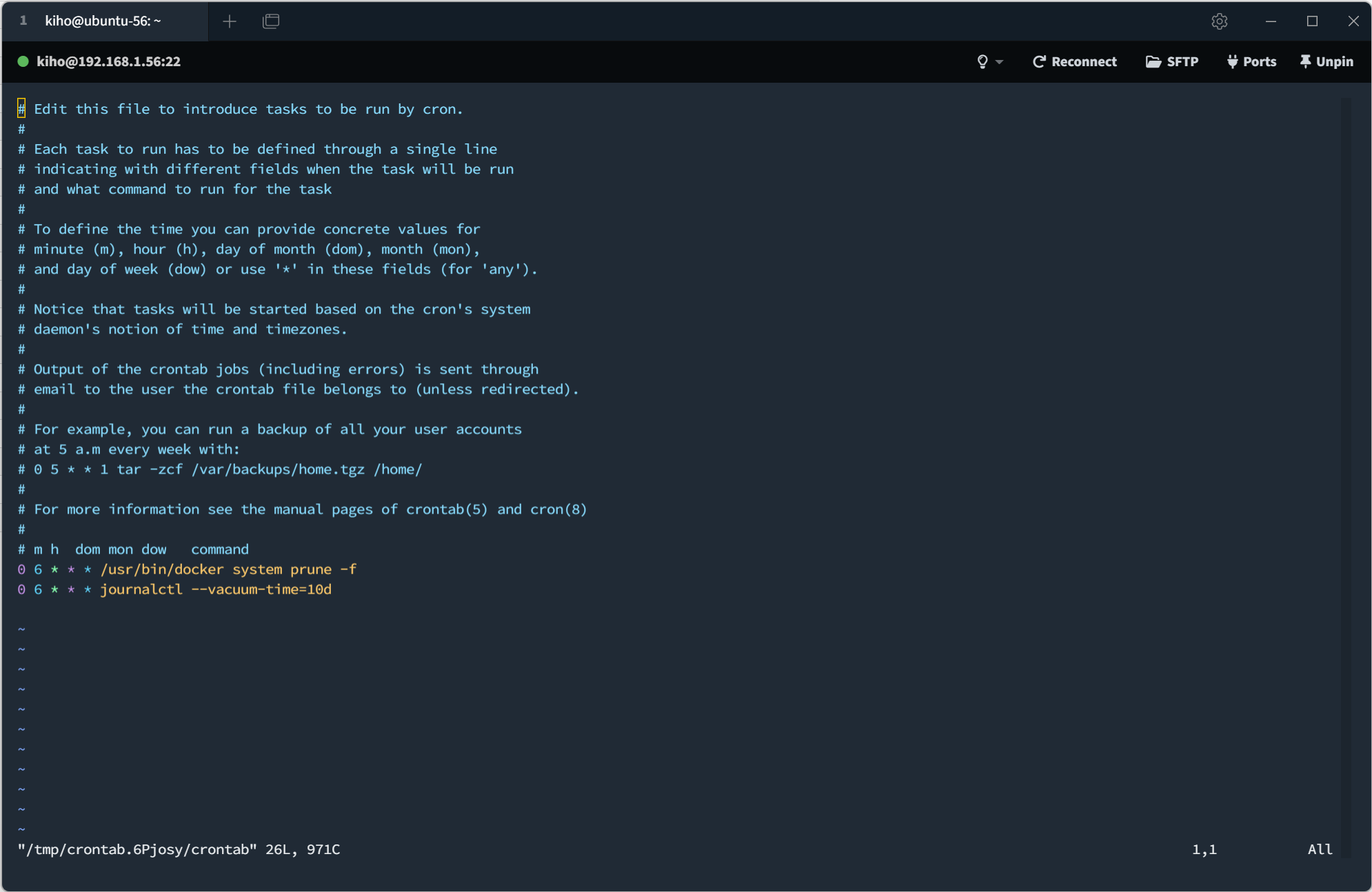
- vm 156 에만 누락된 crontab 작업을 추가하였다.
- 누락된 작업은 docker prune 및 커널 로그 정리를 통한 디스크 공간 확보 작업임
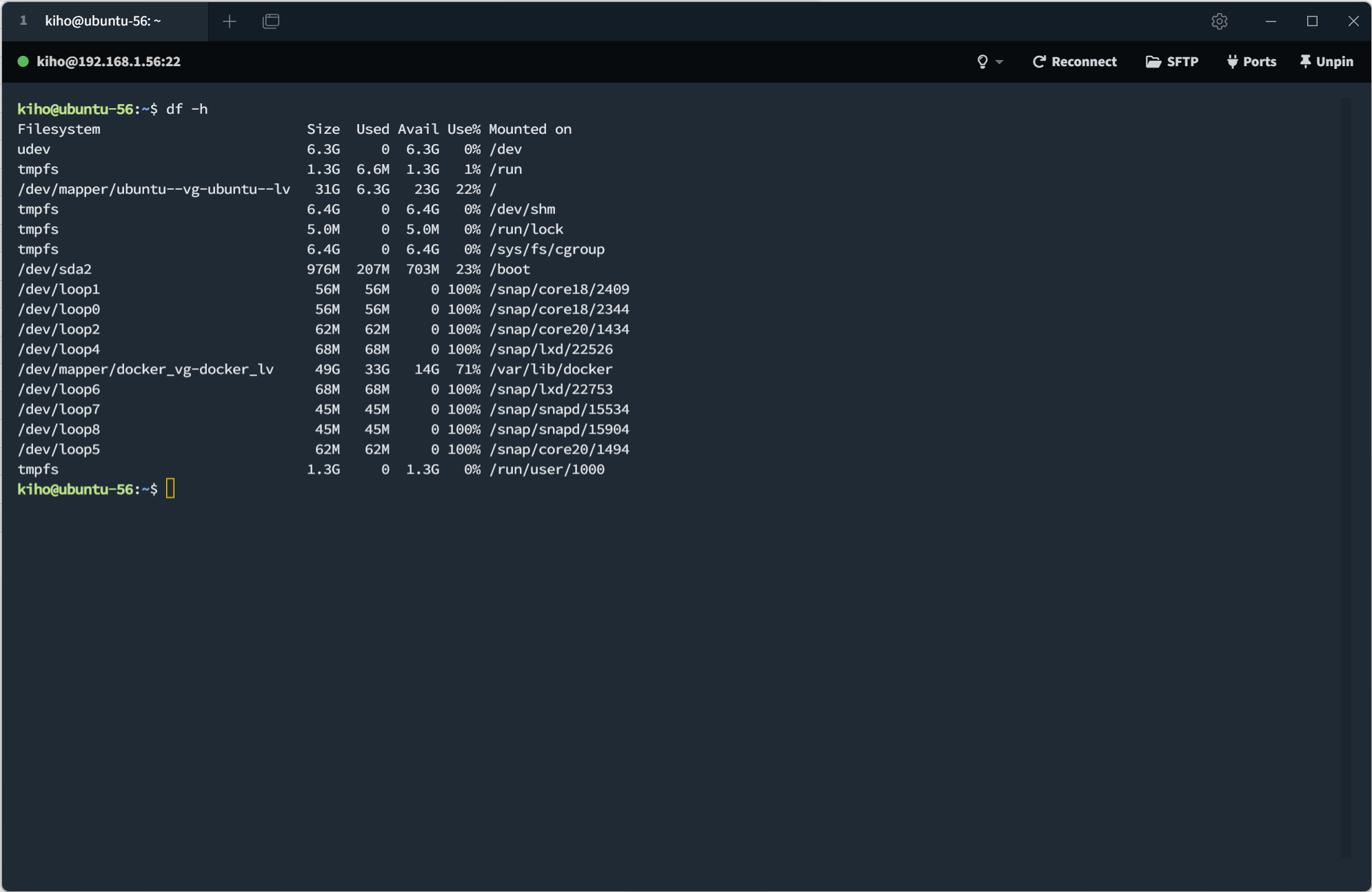
- 디스크 정리 후 여유 공간 확보 (9G -> 14G)
- dmesg 로그에는 구체적인 단서는 찾지 못하였다. (문제가 발생한 12:14 부근 오류 메시지 없음)
결론
- (팩트) netdata 의 156-disk-1 disk i/o 를 보아, 12시 13분 write i/o 발생 시
- (추정) 도커용 볼륨이 가득 차, k8s gc 가 발생하였거나, 오류가 발생한 pod 재기동 시 오작동으로 인해
- (팩트) 대량 및 장시간의 read i/o 발생
- (추정) k8s gc가 완료되었거나, 오작동 pod가 종료되면서
- (팩트) read i/o 종료되며 추가 write i/o 가 발생
정확한 원인은 찾지 못 했지만
- (팩트) 문제의 vm에만 누락되었던 디스크 공간 확보용 crontab 스케줄을 추가하였고
이후 오류 없이 동작하고 있다.
동일 현상 발생으로 인한 결론
- VM 시스템 메모리 사용량 증가
- K8S 실행 위해 swap 메모리 할당 안되어 있음
- 여유 메모리가 줄어들면서 파일 시스템 캐시가 줄어들며, 캐시가 줄어든 만큼 직접적인 디스크 I/O 증가
- I/O wait CPU 증가 및 장시간 hang 발생
- 문제 발생하는 VM에서 실행되는 pod 의 메모리 제한을 줄여서 메모리 부족 상황 방지